
Whether it’s GDPR or any other legal set of rules, personal information included in a product UI or documentation may become a problem sooner or later. This is because the regulations tend to change, and removing the existing content is complicated.
With more and more regulations referring to privacy, this subject has become a part of various research and government developments. It has become a world full of solutions, models and applications. Some of them are free and publicly available, such as IBM’s AI Privacy Toolkit (open-source and available on GitHub) There are also many commercial and sophisticated algorithms trying to meet the challenge. The goal was relatively simple: create anonymised models that maintain the accuracy of the text, are no longer considered personal data, and better protect the privacy in processed data.
Some initial guidance
In the UK, the government publishes advice on what’s happening to GDPR and information traded between the EU and the UK. More detailed guidance is also available at the information commissioners office. It is clear this topic remains valid and affects our daily work more than we could imagine.
In any business context, a safe document is a document that has been anonymised. Slightly more sophisticated is a pseudonymised document, which includes parts that can be decrypted/decoded or replaced when access to a dedicated service is available.
In technical documentation, there are two ways to approach this topic:
- Write or create content that does not include any personal data.
- Remove any personal data from the existing content.
Both are challenging, and both are important.
Want to find out more?
Why bother with data anonymisation?
It is dreadfully common to hear about data leaks and security breaches. If you haven’t checked if one of your accounts has been part of a mass data leak, it’s high time to do so. Dozens of major service providers have been hacked or targeted for attacks, some of them resulting in disclosing huge volumes of information.
Companies are spending millions of dollars on protecting their infrastructure and networks. However, all systems have flaws and bugs. It is a constant struggle and one that sometimes results in failure. Data leaks often include crucial information that should not be made public. Information concerning name, address, bank accounts, e-mails, medical and financial records, etc. Cybercrime has been a fact for many years, and more and more companies are falling victim to extortions and blackmail. The most common scenario nowadays is ransomware, which encrypts a company’s data and destroys it if the demands are not met.

Revealing a company’s secrets is one thing, but disclosing a database holding customer records is another level of trouble. The vast majority of the world holds companies responsible for securing and maintaining personal information about their customers, and any unauthorized access is strictly penalized. GDPR sets forth fines of up to 10 million euros, or up to 2% of its entire global turnover of the preceding fiscal year, whichever is higher.
It is crystal clear that protecting personal data is not just a marketing or political decision. It directly links to business risks and financial stability. It’s not a question of if, but how. If the risk for data leaks is high even in the most technologically savvy corporations, the only way to reduce the impact is to make sure data is stored in a way that does not include personal information. In such cases, GDPR penalties don’t apply. Also, a company’s reputation is taking a very limited hit compared to a situation where customers are notified that their credit card numbers have been stolen.
This is where anonymisation and pseudonymisation come in handy – applying these methods significantly reduces the impact of any data leak or security breach. So, how do you differentiate them? Anonymous data is data that does not include any personal information, which means there is no trail that could lead to it identifying a specific person. Anonymisation is generally about removing data, replacing it with placeholders or overwriting the information with special characters. In some cases, it cannot be applied as data needs to be restored at a specific endpoint in the process. In such cases, data is replaced by a unique pattern that cannot be read or understood without a dedicated algorithm or encryption key. It does not guarantee the full security of anonymised data, but it’s significantly better than storing personal information directly.
Writing with anonymisation in mind
“Hey, let’s use John Doe or Sample Name everywhere!”
It’s a good start, but it’s not that simple. There are areas of UI and documentation where actual personal data may appear. It is not always possible to replace everything with placeholders. Also, if we want to allow an option to revert when necessary (pseudonymisation), we need to be sure each placeholder is different and properly matched to the real data (which then needs to be stored securely somewhere). But that’s the relatively easy part.

The real fun begins when we discuss contextual information. Yes, personal data is ANY information that allows you to identify a person. So, if a sentence says “the guy that I mentioned yesterday” can be linked with a text from the day before, it is also personal information. Even though the quote doesn’t literally use any name or surname, it is personal data.
There are many rules to follow, but the alarm sound should ring in the following situations:
- Historical references,
- Time scheduling references,
- Anything related to the specific person, the way they dress or look
- Any contests, prizes, awards, promotions, medals, ceremonies
- Medical references
- Any events where attendees or speakers can be identified
- E-mail addresses – most of them include personal information
- Domain names
- And many, many others – this is just the tip of an iceberg.
Anonymising or pseudonymising the existing content
If you just realized that personal data may be included in several areas of your products and documentation, have no fear – it affects almost every organization. However, you still need to take corrective actions as regulations are already in place (and fines can be very painful).
Two scenarios exist:
Existing content: this is where you need to decide whether you want to go with anonymisation (irreversibly removing all references to personal data) or pseudonymisation (replacing the personal data with placeholders that can be replaced back in the future).
New content: creating specific writing guidelines for Technical Authors and Software Developers to help them avoid using or generating any data that may directly or indirectly include personal data.
Want to find out more?
Human reviewer vs. automated anonymisation
Anonymisation features have recently been implemented into some Computer-Assisted Tools (CAT). Sometimes they require text pre-processing, sometimes it’s built-in within the environment. The application is still somewhat limited, but it’s already a valid way of speeding up the anonymization process.
It’s worth saying at this stage is clear that human review is necessary to complete the process safely. A translator or a reviewer is checking segments during the regular work. If personal information is recognized, content is manually marked or removed, depending on the selected process. It is the safest approach to removing personal data from any translatable content, but it is the most time-consuming one. This approach is recommended for shorter documents.
Time is of the essence, so it is expected that machines can help us in content anonymisation. The latest developments in Natural Language Processing and Neural Machine Translation fit in the picture of complex IT systems being able to generate more quality content automatically in many languages. Data Anonymisation is a task very close to this domain; identifying text’s semantics, verifying the known lists of names, specific combinations of numbers and letters that build personal data.
The developments, however, are already quite stunning. EU Data Anonymization Tool MAPA has been released for 24 official EU languages, and it’s already usable online:
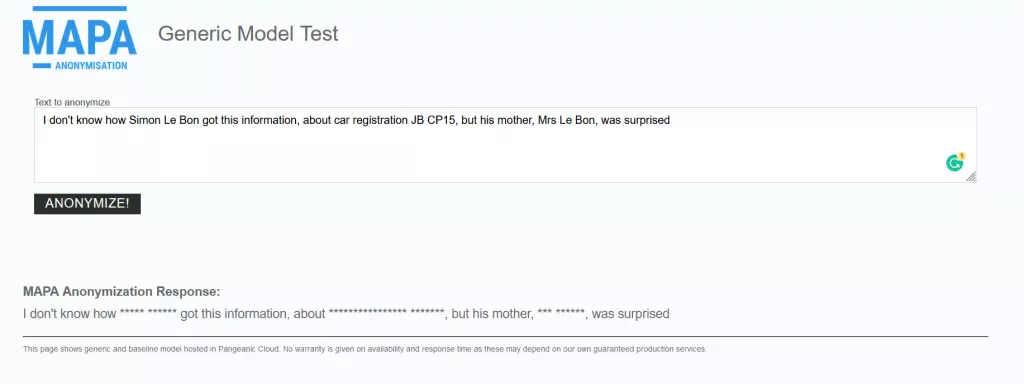
Writing guidelines
The anonymisation of the text may actually start at the very beginning of the writing process. The most common approach is to use meta-data or tagging.
A sample sentence that would be anonymisation-ready might look like this:
I don’t know how <anon>Simon Le Bon</anon> got this information about the car with registration number <anon>JB CP15</anon>, but his mother, <anon>Mrs Le Bon</anon>, was surprised.
Actually, this example shows how challenging this task is because in many situations the contextual information – such as “his mother” – is also personal data. If you can identify the person referenced in the sentence, it’s enough to categorize the content as such.
It’s also worth mentioning that there are some disadvantages of data anonymisation (see this Tech Crunch article for more on that), but in any situation where personal data is processed, it’s simply a necessity. It saves a lot of legal trouble, reduces the cost of storing information and simplifies it. It’s a safe solution for any company which needs to store huge chunks of data linked to a specific user. Chances are, it’s already personal data.
Data anonymisation with 3di
So, if your company understands this challenge and wants to deal with safe content without losing the functionality, it’s high time to consider anonymisation or at least pseudonymisation.
In both cases, 3di will use the latest available technology to verify the text and an experience linguistic team that is trained on GDPR and other privacy regulations to make the necessary amendments to the text.
And if you need to write your documentation from scratch, there’s no better way than to start with anonymisation in mind. Our Technical Authors can apply this while delivering top-notch quality content.
Contact us at contact@3di-info.com and let us help in solving the personal data challenge in your documents once and for all.
Related articles


Localization to drive growth in new markets: when and how?
For many businesses, investing in quality translation and localization can help drive growth.

Localizing Single-Source Content: 3 Tips to Avoid Problems
Single-sourcing has been long-established as one of the core principles of modern technical and user…